बाइनरी सिस्टम में अक्षरों को कैसे एन्कोड किया जाता है। बाइनरी कोड क्या है? कंप्यूटर मेमोरी में टेक्स्ट की जानकारी कैसी दिख सकती है
पाठ जानकारी की बाइनरी कोडिंग
60 के दशक के अंत के बाद से, कंप्यूटरों का उपयोग टेक्स्ट सूचनाओं को संसाधित करने के लिए तेजी से किया गया है, और अब अधिकांश व्यक्तिगत कम्प्यूटर्सदुनिया में (और अधिकांश समय) पाठ्य सूचना के प्रसंस्करण पर कब्जा कर लिया जाता है।
परंपरागत रूप से, एक वर्ण को एन्कोड करने के लिए, 1 बाइट के बराबर जानकारी की मात्रा का उपयोग किया जाता है, अर्थात I \u003d 1 बाइट \u003d 8 बिट्स।
नाइजीरिया के इमैनुएल पूछते हैं: "अक्षरों को बाइनरी कोड में कैसे बदला जाता है?"। यदि ऐसा है, तो आप एक महान प्रश्न पूछ रहे हैं, क्योंकि हम अक्षरों को कैसे परिवर्तित करते हैं, इस प्रश्न की वास्तव में व्याख्या नहीं की गई है। बड़ा सवाल यह है कि "आप किसी अक्षर को संख्या में कैसे बदलते हैं?" क्योंकि यदि आप किसी अक्षर को किसी संख्या में परिवर्तित कर सकते हैं, तो आप हमारे मूल रूपांतरण पृष्ठ की जानकारी का उपयोग उस संख्या को बाइनरी में बदलने के लिए कर सकते हैं। तो कंप्यूटर एक अक्षर से संख्या में कैसे परिवर्तित होता है?
प्रत्येक वर्ण में समान संख्या में बाइनरी बिट्स होने चाहिए - अन्यथा किसी को पता नहीं चलेगा कि एक वर्ण कहाँ समाप्त होता है और अगला शुरू होता है। हम प्रत्येक चार तिथियों के बीच एक स्थान रखते हैं, उसी कारण से हम आधार दस अल्पविराम लगाते हैं - यह हमें संख्याओं के लंबे तारों को अधिक आसानी से पढ़ने में मदद करता है।
एक कैरेक्टर को एनकोड करने में 1 बाइट की जानकारी लगती है।
यदि हम प्रतीकों को संभावित घटनाओं के रूप में मानते हैं, तो सूत्र (2.1) का उपयोग करके हम गणना कर सकते हैं कि कितने अलग-अलग प्रतीकों को एन्कोड किया जा सकता है:
एन = 2 मैं = 2 8 = 256।
रूसी और लैटिन वर्णमाला के अपरकेस और लोअरकेस अक्षरों, संख्याओं, संकेतों, ग्राफिक प्रतीकों आदि सहित पाठ्य जानकारी का प्रतिनिधित्व करने के लिए वर्णों की यह संख्या काफी है।
ठीक है, तो अब से, हमें केवल यह जानने की जरूरत है कि कौन से अक्षर किस संख्या से निरूपित होते हैं। यहां आपके लिए एक संक्षिप्त संदर्भ दिया गया है। इसका मतलब है कि लोअरकेस अक्षरों में अपरकेस अक्षरों की तुलना में एक अलग संख्या असाइन की गई है। अब आप कुछ चीजों के बारे में सोच रहे होंगे, जैसे "65 वर्ष की आयु से पहले क्या होता है?" और "ऊपरी और निचले मामले के बीच अंतर क्यों है?"।
पहले प्रश्न का उत्तर यह है कि इन रिक्त स्थानों में अन्य वर्ण हैं - संख्याएँ, विराम चिह्न, विशेष नियंत्रण वर्ण। अपर केस और लोअर केस अक्षरों के बीच अंतर होने का कारण यह है कि यह "ए" से "32" अधिक बनाता है। यह बहुत आसान है क्योंकि 32 2 की शक्ति है, इसलिए ऊपरी और निचले मामले के बीच बदलाव का मतलब सिर्फ एक बिट बदलाव है।
एन्कोडिंग यह है कि प्रत्येक वर्ण को 0 से 255 तक या उसके अनुरूप एक अद्वितीय दशमलव कोड दिया जाता है बाइनरी कोड 000000000 से 11111111 तक। इस प्रकार, एक व्यक्ति पात्रों को उनकी शैलियों से और एक कंप्यूटर को उनके कोड द्वारा अलग करता है।
जब कंप्यूटर में टेक्स्ट जानकारी दर्ज की जाती है, तो यह बाइनरी एन्कोडिंग, चरित्र छवि को इसके बाइनरी कोड में बदल दिया जाता है। उपयोगकर्ता कीबोर्ड पर एक प्रतीक के साथ एक कुंजी दबाता है, और आठ विद्युत आवेगों (प्रतीक का बाइनरी कोड) का एक निश्चित क्रम कंप्यूटर में प्रवेश करता है। कैरेक्टर कोड में स्टोर होता है यादृच्छिक अभिगम स्मृतिकंप्यूटर, जहां यह एक बाइट लेता है।
आप ऐसा क्यों करना चाहते हो? ठीक है, यदि आप स्थान बचाना नहीं चाहते हैं और आपको मूल अपरकेस वर्णमाला के अलावा किसी और चीज़ की परवाह नहीं है, तो शायद आप ऐसा नहीं करेंगे। आप देखिए, यदि आप केवल अपरकेस अक्षरों की परवाह करते हैं, तो आप यह रूपांतरण इस तरह कर सकते हैं।
ध्वनियों की बाइनरी कोडिंग
क्योंकि अब आपकी सबसे बड़ी संख्या 26 है, जो कि 25 से कम है। आप लगभग 38% पृष्ठ स्थान बचाएंगे। चूंकि आपके पास तालिका में 32 वर्ण स्थान होना चाहिए और आप केवल 26 तक ही उपयोग करते हैं, आप दूसरों का भी उपयोग कर सकते हैं। शायद कुछ विराम चिह्न हैं?
कंप्यूटर स्क्रीन पर एक चरित्र को प्रदर्शित करने की प्रक्रिया में, रिवर्स प्रक्रिया की जाती है - डिकोडिंग, यानी चरित्र कोड को उसकी छवि में परिवर्तित करना।
यह महत्वपूर्ण है कि एक प्रतीक के लिए एक विशिष्ट कोड का असाइनमेंट सहमति का मामला है, जो कोड तालिका में तय किया गया है। पहले 33 कोड (0 से 32 तक) वर्णों के अनुरूप नहीं हैं, लेकिन संचालन (लाइन फीड, स्पेस एंट्री, और इसी तरह) के अनुरूप हैं।
कंप्यूटर बाइनरी कोड का उपयोग क्यों करता है
या आप 64 वर्णों वाली एक तालिका बना सकते हैं, जो या तो आपको बहुत अधिक विराम चिह्न, या संख्याएँ, या लोअरकेस वर्णमाला जोड़ने की अनुमति देगा। लेकिन अब आप प्रति वर्ण छह बाइनरी अंकों का उपयोग कर रहे हैं, इसलिए आप इतना स्थान नहीं बचाते हैं।
या आप अपने चरित्र आरेख को पूरी तरह से गड़बड़ कर सकते हैं, जिससे अन्य लोगों के लिए इसे समझना मुश्किल हो जाता है। यह कई लाइट स्विच वाले कंप्यूटर की तरह है, और प्रत्येक लाइट स्विच केवल एक लाइट बल्ब को नियंत्रित करता है। मान लीजिए कि आपके पास दो लाइट स्विच थे। चार हैं विभिन्न तरीकेजिससे हम इन स्विच को फ्लिप कर सकते हैं।
33 से 127 तक के कोड अंतरराष्ट्रीय हैं और लैटिन वर्णमाला, संख्याओं, संकेतों के वर्णों के अनुरूप हैं अंकगणितीय आपरेशनसऔर विराम चिह्न।
128 से 255 तक के कोड राष्ट्रीय हैं, यानी राष्ट्रीय एन्कोडिंग में, अलग-अलग वर्ण एक ही कोड के अनुरूप हैं। दुर्भाग्य से, वर्तमान में रूसी अक्षरों (KOI8, СР1251, СР866, Mac, ISO - तालिका 1.3) के लिए पांच अलग-अलग कोड टेबल हैं, इसलिए एक एन्कोडिंग में बनाए गए टेक्स्ट दूसरे में सही ढंग से प्रदर्शित नहीं होंगे।
बाइनरी इनमें से प्रत्येक संयोजन को लेता है और उसे एक संख्या प्रदान करता है, उदा। यदि हम एक और बल्ब में जोड़ते हैं, तो हम इसे पॉइंटर 2 से दोगुना बड़ा करते हैं। फिर, यदि सभी बल्बों को शामिल किया जाता है, तो बिंदु का मान होगा 4 2 1 = और यदि हम दूसरे बल्ब में जोड़ते हैं, हम इसे 8 बिंदुओं पर रखेंगे। जैसा कि आप देख सकते हैं, वास्तव में एक बड़ा कमरा बनाने में बहुत सारे प्रकाश बल्ब लगते हैं!
अंत में, हालांकि हम इनमें से प्रत्येक बल्ब को बिंदु मान देते हैं, जब हम उन्हें लिखते हैं, तब भी हम उन्हें केवल इकाई और शून्य के रूप में लिखते हैं। एक का मतलब ऑन और जीरो का मतलब ऑफ होता है। तो मान लीजिए कि हमारे पास 8 बल्ब थे और वे इस तरह स्थापित किए गए थे।
वर्तमान में, एक नया अंतर्राष्ट्रीय मानकयूनिकोड, जो प्रत्येक वर्ण के लिए एक बाइट नहीं, बल्कि दो आवंटित करता है, इसलिए इसका उपयोग 256 वर्णों को नहीं, बल्कि N = 216 = = 65536 विभिन्न वर्णों को एन्कोड करने के लिए किया जा सकता है। यह एन्कोडिंग समर्थित है नवीनतम संस्करणमाइक्रोसॉफ्ट विंडोज और ऑफिस प्लेटफॉर्म (1997 से)।
प्रत्येक एन्कोडिंग अपनी कोड तालिका द्वारा निर्दिष्ट किया जाता है। जैसा कि तालिका से देखा जा सकता है। 1.3, अलग-अलग एन्कोडिंग में एक ही बाइनरी कोड के लिए अलग-अलग वर्ण असाइन किए गए हैं।
इन आठ दीपकों के बिंदु मान। इसलिए, हम कहेंगे कि बल्बों का क्रम इसके लायक है। आगे बढ़ें और एन्कोडर में टेक्स्ट टाइप करें। कंप्यूटर उन अक्षरों को संख्याओं में बदल देता है और फिर उन संख्याओं को बाइनरी में बदल देता है! क्या आप जानते हैं कि कंप्यूटर पर किसी भी अक्षर को लिखने में 8 लाइट बल्ब लगते हैं? तो 5 अक्षरों वाला एक शब्द 40 बल्ब लेगा! इस पेज को बनाने के लिए आपके विचार में कितने बल्ब हैं?
कंप्यूटर मेमोरी में टेक्स्ट की जानकारी कैसी दिख सकती है?
कंप्यूटर के अंदर सभी डेटा विद्युत संकेतों की एक श्रृंखला के रूप में प्रेषित होते हैं जो या तो चालू या बंद होते हैं। इसलिए, कंप्यूटर के लिए पाठ, छवियों और ध्वनि सहित किसी भी डेटा को संसाधित करने के लिए, उन्हें एक रूप में परिवर्तित किया जाना चाहिए। यदि डेटा को बाइनरी में परिवर्तित नहीं किया जाता है - 1s और 0s की एक श्रृंखला - कंप्यूटर बस इसे समझ नहीं पाएगा या इसे संसाधित करने में सक्षम नहीं होगा।
उदाहरण के लिए, CP1251 एन्कोडिंग में संख्यात्मक कोड 221, 194, 204 का अनुक्रम "कंप्यूटर" शब्द बनाता है, जबकि अन्य एन्कोडिंग में यह वर्णों का एक अर्थहीन सेट होगा।
सौभाग्य से, ज्यादातर मामलों में उपयोगकर्ता को रीकोडिंग के बारे में चिंता करने की ज़रूरत नहीं है पाठ दस्तावेज़, क्योंकि यह अनुप्रयोगों में निर्मित विशेष कनवर्टर प्रोग्राम द्वारा किया जाता है।
जब कीबोर्ड पर किसी भी कुंजी को दबाया जाता है, तो उसे एक बाइनरी नंबर में बदलने की आवश्यकता होती है ताकि इसे कंप्यूटर द्वारा संसाधित किया जा सके और स्क्रीन पर एक विशिष्ट वर्ण दिखाई दे सके। एक कोड जहां प्रत्येक संख्या एक वर्ण का प्रतिनिधित्व करती है, का उपयोग टेक्स्ट को बाइनरी में बदलने के लिए किया जा सकता है। एक कोड कहा जाता है जिसका उपयोग हम ऐसा करने के लिए कर सकते हैं।
यदि आप यूरोपीय भाषाओं में उच्चारण या सिरिलिक और चीनी मंदारिन जैसे बड़े अक्षरों का उपयोग करना चाहते हैं, तो आपको अधिक वर्णों की आवश्यकता है। तो एक और कोड बनाया गया जिसे कहा जाता है। इसका मतलब था कि कंप्यूटर का इस्तेमाल अलग-अलग भाषाओं का इस्तेमाल करने वाले लोग कर सकते हैं।
संख्यात्मक वर्ण कोड का निर्धारण
1. एमएस वर्ड 2002 टेक्स्ट एडिटर लॉन्च करें। [इन्सर्ट-सिंबल ...] कमांड दर्ज करें। स्क्रीन पर एक डायलॉग बॉक्स दिखाई देगा। चिन्ह, प्रतीक. संवाद बॉक्स के मध्य भाग में एक विशिष्ट फ़ॉन्ट के लिए वर्ण तालिका होती है (उदाहरण के लिए, टाइम्स न्यू रोमन)।
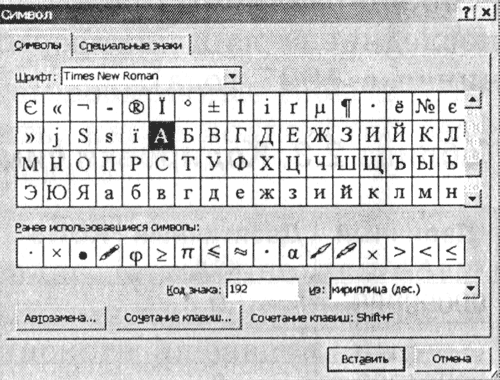 |
वर्ण क्रम से बाएं से दाएं और वर्ण से शुरू होकर पंक्ति से पंक्तिबद्ध होते हैं अंतरिक्षऊपरी बाएँ कोने में और तालिका के निचले दाएँ कोने में "i" अक्षर से समाप्त होता है।
पाठ जानकारी की बाइनरी कोडिंग
अंग्रेजी कीबोर्ड वर्णों का प्रतिनिधित्व करने के लिए उपयोग किया जाने वाला 7-बिट वर्ण सेट। एक बाइनरी नंबर सिस्टम जिसमें दो अंक होते हैं, 0, और इसे बेस बिट के रूप में भी जाना जाता है। फ़ाइल आकार को कम करने का एक तरीका, विशेष रूप से डिजिटल मीडिया जैसे फ़ोटो, ऑडियो और वीडियो पर। डेटा सूचना की इकाइयाँ। गणना में विभिन्न प्रकार के डेटा हो सकते हैं, जिसमें पूर्णांक, वर्ण और बूलियन शामिल हैं। लोगों द्वारा सबसे अधिक उपयोग की जाने वाली संख्या प्रणाली। इसमें 0 से 10 अद्वितीय अंक होते हैं जिन्हें दशमलव या मूल संख्यात्मक जानकारी के रूप में भी जाना जाता है, जिन्हें असतत मानों के रूप में संग्रहीत किया जाता है, जिन्हें आमतौर पर संख्याओं के रूप में दर्शाया जाता है। यह डेटा का एक सेट है जो अन्य डेटा का वर्णन करता है और जानकारी देता है। अधिकांश मीडिया प्लेयर के साथ संगत। चलती छवि विशेषज्ञों के एक समूह द्वारा विकसित - परत पिक्सेल। एक चित्र तत्व डिजिटल बिटमैप या कंप्यूटर स्क्रीन पर रंग का एकल बिंदु है। अनुमति। एक छवि में देखे जा सकने वाले विवरण की मात्रा - छवि का रिज़ॉल्यूशन जितना अधिक होगा, उतना ही अधिक विवरण प्रदान किया जाएगा। इसे डॉट्स प्रति इंच में मापा जाता है। नमूना दर। प्रति सेकंड कितने डेटा नमूने प्राप्त होते हैं। यह आमतौर पर हर्ट्ज़ में मापा जाता है, उदाहरण के लिए एक ऑडियो फ़ाइल आमतौर पर 1 kHz नमूनों का उपयोग करती है। एन्कोडिंग में, जब संख्याओं, अक्षरों या शब्दों को वर्णों के एक विशिष्ट समूह द्वारा दर्शाया जाता है, तो संख्या, अक्षर या शब्द को एन्कोडेड कहा जाता है।
एक प्रतीक चुनें और ड्रॉप-डाउन सूची से से:एन्कोडिंग प्रकार। टेक्स्ट बॉक्स में साइन कोड:इसका न्यूमेरिक कोड दिखाई देगा।
संख्यात्मक कोड द्वारा वर्ण दर्ज करना
1. मानक कार्यक्रम चलाएँ स्मरण पुस्तक. अतिरिक्त संख्यात्मक कीपैड का उपयोग करते हुए, कुंजी (Alt) को दबाए रखते हुए, संख्या 0224 दर्ज करें, कुंजी (Alt) छोड़ें। दस्तावेज़ में प्रतीक "ए" दिखाई देगा। 0225 से 0233 तक संख्यात्मक कोड के लिए प्रक्रिया दोहराएं। दस्तावेज़ में विंडोज़ एन्कोडिंग (सीपी1251) में 12 "abcgdej" वर्णों का एक क्रम दिखाई देगा।
वर्णों के समूह को कोड कहते हैं। डिजिटल डेटा को बाइनरी बिट्स के समूह के रूप में दर्शाया, संग्रहीत और प्रसारित किया जाता है। इस समूह को बाइनरी कोड भी कहा जाता है। बाइनरी कोड को एक संख्या के साथ-साथ एक अल्फ़ान्यूमेरिक अक्षर द्वारा दर्शाया जाता है। नीचे उन लाभों की सूची दी गई है जो बाइनरी ऑफ़र करते हैं।
बाइनरी कोड का वर्गीकरण
बाइनरी कोड विश्लेषण और डिजाइन करते हैं डिजिटल सर्किटअगर हम बाइनरी कोड का उपयोग करते हैं।
- बाइनरी कोड कंप्यूटर अनुप्रयोगों के लिए उपयुक्त हैं।
- बाइनरी कोड डिजिटल संचार के लिए उपयुक्त हैं।
2. अतिरिक्त संख्यात्मक कीपैड का उपयोग करते हुए, (Alt) कुंजी को दबाए रखते हुए, संख्या 224 दर्ज करें, दस्तावेज़ में प्रतीक "p" दिखाई देगा। 225 से 233 तक संख्यात्मक कोड के लिए प्रक्रिया को दोहराएं, दस्तावेज़ में MS-DOS एन्कोडिंग (CP866) में 12 वर्णों "rstufhtschshsch" का एक क्रम दिखाई देगा।
 |
व्यावहारिक कार्य
हस्ताक्षरित भिन्नात्मक संख्या
दशमलव अंक 0 को व्यक्त करने के लिए कई कोडिंग सिस्टम का उपयोग किया जाता है। इन कोडों में, प्रत्येक दशमलव अंकचार बिट्स के समूह द्वारा प्रतिनिधित्व किया। इस प्रकार के बाइनरी कोड में, स्थितीय भार निर्दिष्ट नहीं किए जाते हैं। यह वह भारित कोड है जिसका उपयोग व्यक्त करने के लिए किया जाता है दशमलव संख्याएं. अतिरेक -3 कोड निम्नानुसार प्राप्त किए जाते हैं।

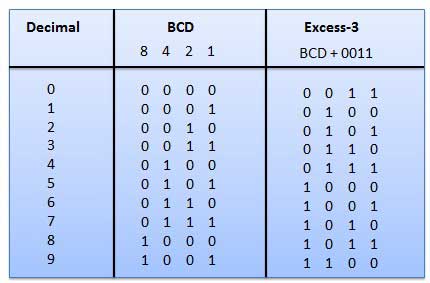
यह एक भारित कोड है, और ये अंकगणितीय कोड नहीं हैं। इसका मतलब है कि बिट स्थिति को निर्दिष्ट कोई विशिष्ट भार नहीं है। इसकी एक बहुत ही खास विशेषता है: हर बार दशमलव संख्या बढ़ने पर केवल एक बिट बदलेगा, जैसा कि अंजीर में दिखाया गया है। क्योंकि एक बार में केवल एक बिट बदलता है, ग्रे कोड को सिंगल डिस्टेंस कोड कहा जाता है। ग्रे कोड एक चक्रीय कोड है। सीरियल कोड का उपयोग अंकगणितीय ऑपरेशन के लिए नहीं किया जा सकता है।
1.29 एक कैरेक्टर टेबल (एमएस वर्ड) का उपयोग करके, "कंप्यूटर" शब्द के लिए विंडोज एन्कोडिंग (सीपी 1251) में दशमलव संख्यात्मक कोड का अनुक्रम लिखें।
1.30. नोटपैड का उपयोग करते हुए, निर्धारित करें कि विंडोज एन्कोडिंग (CP1251) में कौन सा शब्द संख्यात्मक कोड के अनुक्रम द्वारा दिया गया है: 225, 224, 233,242।
1.31. KOI8 और ISO कोड में अक्षरों का कौन सा क्रम CP1251 एन्कोडिंग में लिखे गए "कंप्यूटर" शब्द के अनुरूप होगा?
बाइनरी एन्कोडेड दशमलव कोड
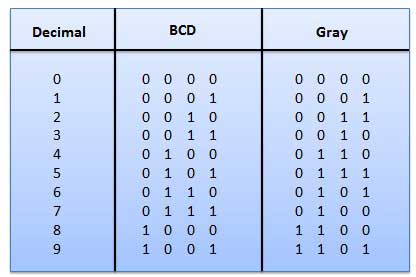
शाफ्ट स्थिति सेंसर एक कोड शब्द उत्पन्न करता है जो शाफ्ट की कोणीय स्थिति का प्रतिनिधित्व करता है। शाफ्ट एन्कोडर में ग्रे कोड का व्यापक रूप से उपयोग किया जाता है। . इस कोड में, प्रत्येक दशमलव अंक को 4-बिट बाइनरी संख्या द्वारा दर्शाया जाता है। 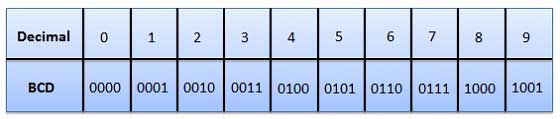
- यह दशमलव प्रणाली के समान ही है।
- हमें केवल 0 से 9 तक की दशमलव संख्याओं के बाइनरी समतुल्य को याद रखने की आवश्यकता है।
कंप्यूटर बड़ी मात्रा में सूचनाओं को संसाधित करता है। ऑडियो फ़ाइलें, चित्र, टेक्स्ट - इन सभी को वापस चलाने या स्क्रीन पर प्रदर्शित करने की आवश्यकता है। बाइनरी एन्कोडिंग क्यों है सार्वभौमिक विधिकिसी तकनीकी उपकरण की प्रोग्रामिंग जानकारी?
एन्क्रिप्शन एन्क्रिप्शन से कैसे अलग है?
अक्सर लोग "एन्कोडिंग" और "एन्क्रिप्शन" की अवधारणाओं की बराबरी करते हैं, जब वास्तव में उनके अलग-अलग अर्थ होते हैं। इस प्रकार, एन्क्रिप्शन जानकारी को छिपाने के लिए परिवर्तित करने की प्रक्रिया है। जिस व्यक्ति ने पाठ को बदला है, या विशेष रूप से प्रशिक्षित लोग, अक्सर इसे समझ सकते हैं। कोडिंग का उपयोग सूचनाओं को संसाधित करने और इसके साथ काम को सरल बनाने के लिए किया जाता है। आमतौर पर, एक सामान्य एन्कोडिंग तालिका का उपयोग किया जाता है, जो सभी के लिए परिचित है। यह भी कंप्यूटर में बनाया गया है।
इन वर्णों को अपरकेस और लोअरकेस अक्षरों, 0 से 9 तक की संख्या, विराम चिह्न और अन्य प्रतीकों के साथ 26 वर्णों का प्रतिनिधित्व करना चाहिए। अल्फ़ान्यूमेरिक कोड ऐसे कोड होते हैं जो संख्याओं और वर्णानुक्रमिक वर्णों का प्रतिनिधित्व करते हैं। ज्यादातर मामलों में, ऐसे कोड अन्य प्रतीकों का भी प्रतिनिधित्व करते हैं, जैसे कि एक चरित्र और विभिन्न निर्देश, जो जानकारी देने के लिए आवश्यक हैं। अल्फ़ान्यूमेरिक कोड में कम से कम 10 अंक और वर्णमाला के 26 अक्षर होने चाहिए, अर्थात। कुल 36 तत्व। निम्नलिखित तीन अल्फ़ान्यूमेरिक कोड आमतौर पर डेटा का प्रतिनिधित्व करने के लिए उपयोग किए जाते हैं।
छवियों को बाइनरी कोड में एन्कोड करना
इस सूचना एन्कोडिंग प्रणाली को बाइनरी कहा जाता है। यह कोडिंग का एक रूप है जो कंप्यूटर को काम करने की अनुमति देता है। बाइनरी कोड जानकारी को एन्कोड करने के लिए दो राज्यों का उपयोग करता है। इसे "दशमलव आधार" कहा जाता है। हालाँकि, पुरानी सभ्यताएँ और यहाँ तक कि कुछ आधुनिक अनुप्रयोग अन्य संख्या आधारों का उपयोग और उपयोग करते हैं।
बाइनरी कोडिंग का सिद्धांत
बाइनरी कोडिंग केवल दो वर्णों के उपयोग पर आधारित है - 0 और 1 - उपयोग की गई जानकारी को संसाधित करने के लिए विभिन्न उपकरण. इन संकेतों को अंग्रेजी में बाइनरी डिजिट कहा जाता था - बाइनरी डिजिट, या बिट। प्रत्येक वर्ण कंप्यूटर की 1 बिट मेमोरी लेता है। बाइनरी कोडिंग एक सार्वभौमिक सूचना प्रसंस्करण विधि क्यों है? मुद्दा यह है कि कंप्यूटर के लिए कम वर्णों को संसाधित करना आसान होता है। पीसी की उत्पादकता सीधे इस पर निर्भर करती है: डिवाइस को जितने कम कार्यात्मक कार्य करने की आवश्यकता होती है, काम की गति और गुणवत्ता उतनी ही अधिक होती है। 
बाइनरी कोडिंग का सिद्धांत केवल प्रोग्रामिंग में ही नहीं पाया जाता है। बारी-बारी से बहरे और सोनोरस ड्रम बीट्स की मदद से पोलिनेशिया के निवासियों ने एक-दूसरे को सूचना प्रसारित की। एक समान सिद्धांत लागू होता है जहां संदेश देने के लिए लंबी और छोटी ध्वनियों का उपयोग किया जाता है। "टेलीग्राफिक वर्णमाला" आज भी प्रयोग में है।
बाइनरी एन्कोडिंग का उपयोग कहाँ किया जाता है?
कंप्यूटर में बाइनरी सर्वव्यापी है। प्रत्येक फ़ाइल, चाहे वह संगीत हो या पाठ, को प्रोग्राम किया जाना चाहिए ताकि इसे आसानी से संसाधित किया जा सके और बाद में पढ़ा जा सके। बाइनरी कोडिंग सिस्टम प्रतीकों और संख्याओं, ऑडियो फाइलों, ग्राफिक्स के साथ काम करने के लिए उपयोगी है।
संख्याओं की बाइनरी एन्कोडिंग
अब कंप्यूटर में, संख्याओं को एक एन्कोडेड रूप में प्रस्तुत किया जाता है जो एक सामान्य व्यक्ति के लिए समझ से बाहर है। अरबी अंकों का उपयोग, जैसा कि हम कल्पना करते हैं, प्रौद्योगिकी के लिए तर्कहीन है। इसका कारण प्रत्येक संख्या के लिए एक अद्वितीय प्रतीक निर्दिष्ट करने की आवश्यकता है, जो कभी-कभी करना असंभव है।

दो संख्या प्रणालियाँ हैं: स्थितीय और गैर-स्थितीय। गैर-स्थितीय प्रणाली लैटिन अक्षरों के उपयोग पर आधारित है और हमें इस रूप में परिचित है। लिखने का यह तरीका समझना काफी कठिन है, इसलिए इसे छोड़ दिया गया था।
स्थितीय संख्या प्रणाली आज भी प्रयोग की जाती है। इसमें बाइनरी, डेसीमल, ऑक्टल और यहां तक कि हेक्साडेसिमल सूचनाओं की एन्कोडिंग शामिल है।
हम दैनिक जीवन में दशमलव कोडिंग प्रणाली का उपयोग करते हैं। ये हमारे लिए अभ्यस्त हैं जो हर व्यक्ति के लिए स्पष्ट हैं। संख्याओं की बाइनरी एन्कोडिंग केवल शून्य और एक के उपयोग में भिन्न होती है।
पूर्णांकों को 2 से विभाजित करके बाइनरी कोडिंग सिस्टम में परिवर्तित किया जाता है। परिणामी भागफल को भी 2 चरणों में विभाजित किया जाता है जब तक कि परिणाम 0 या 1 न हो। उदाहरण के लिए, संख्या 123 10 में बायनरी सिस्टम 1111011 2 के रूप में दर्शाया जा सकता है। और संख्या 20 10 10100 2 की तरह दिखेगी।
इंडेक्स 10 और 2 को क्रमशः दशमलव और बाइनरी कोडिंग सिस्टम द्वारा दर्शाया जाता है। बाइनरी कैरेक्टर का उपयोग विभिन्न संख्या प्रणालियों में प्रतिनिधित्व मूल्यों के साथ काम करना आसान बनाने के लिए किया जाता है।
दशमलव प्रोग्रामिंग विधियां "फ्लोटिंग पॉइंट" पर आधारित हैं। दशमलव से बाइनरी कोडिंग सिस्टम में मान को सही ढंग से बदलने के लिए, सूत्र N = M x qp का उपयोग करें। M मंटिसा है (बिना किसी क्रम के किसी संख्या का व्यंजक), p N के मान का क्रम है, और q कोडिंग प्रणाली का आधार है (हमारे मामले में 2)।
सभी संख्याएँ सकारात्मक नहीं हैं। सकारात्मक और नकारात्मक संख्याओं के बीच अंतर करने के लिए, कंप्यूटर साइन को एन्कोड करने के लिए 1 बिट के लिए जगह छोड़ देता है। यहां शून्य धन चिह्न का प्रतिनिधित्व करता है और एक ऋण चिह्न का प्रतिनिधित्व करता है।
ऐसी संख्या प्रणाली का उपयोग करने से कंप्यूटर के लिए संख्याओं के साथ कार्य करना आसान हो जाता है। यही कारण है कि कंप्यूटिंग प्रक्रियाओं में बाइनरी कोडिंग सार्वभौमिक है।

पाठ जानकारी की बाइनरी कोडिंग
वर्णमाला के प्रत्येक वर्ण को शून्य और एक के अपने सेट द्वारा एन्कोड किया गया है। पाठ में अलग-अलग वर्ण होते हैं: अक्षर (अपरकेस और लोअरकेस), अंकगणितीय संकेत, और कई अन्य मान। पाठ्य जानकारी को कूटबद्ध करने के लिए 00000000 से 11111111 तक लगातार 8 बाइनरी मानों के उपयोग की आवश्यकता होती है। इस प्रकार, 256 विभिन्न वर्णों को परिवर्तित किया जा सकता है।
पाठ एन्कोडिंग में भ्रम से बचने के लिए, प्रत्येक वर्ण के लिए विशेष मान तालिकाओं का उपयोग किया जाता है। उनमें लैटिन वर्णमाला, अंकगणितीय संकेत और विशेष संकेत (उदाहरण के लिए, €, , और अन्य) शामिल हैं। गैप वर्ण 128-255 देश की राष्ट्रीय वर्णमाला को कूटबद्ध करते हैं।
1 कैरेक्टर को एनकोड करने में 8 बिट मेमोरी लगती है। गणनाओं को सरल बनाने के लिए, 8 बिट 1 बाइट के बराबर होते हैं, इसलिए पाठ जानकारी के लिए कुल डिस्क स्थान बाइट्स में मापा जाता है।

अधिकांश पर्सनल कंप्यूटर एक मानक ASCII (सूचना इंटरचेंज के लिए अमेरिकी मानक कोड) एन्कोडिंग तालिका से लैस हैं। अन्य तालिकाओं का भी उपयोग किया जाता है, जिसमें पाठ सूचना एन्कोडिंग प्रणाली अलग होती है। उदाहरण के लिए, पहले ज्ञात वर्ण एन्कोडिंग को KOI-8 (8-बिट सूचना विनिमय कोड) कहा जाता है, और यह UNIX चलाने वाले कंप्यूटरों पर काम करता है। इसके अलावा व्यापक रूप से पाया गया CP1251 कोड तालिका है, जिसे बनाया गया था ऑपरेटिंग सिस्टमखिड़कियाँ।
ध्वनियों की बाइनरी कोडिंग
प्रोग्रामिंग जानकारी के लिए बाइनरी एन्कोडिंग इतनी बहुमुखी विधि का एक अन्य कारण ऑडियो फाइलों के साथ काम करते समय इसका उपयोग करना आसान है। कोई भी संगीत विभिन्न आयाम और आवृत्ति की ध्वनि तरंगें हैं। ध्वनि का आयतन और उसकी पिच इन मापदंडों पर निर्भर करती है।
ध्वनि तरंग को प्रोग्राम करने के लिए, कंप्यूटर इसे सशर्त रूप से कई भागों, या "नमूने" में विभाजित करता है। ऐसे नमूनों की संख्या बड़ी हो सकती है, इसलिए शून्य और इकाई के 65536 विभिन्न संयोजन हैं। तदनुसार, आधुनिक कंप्यूटर 16-बिट साउंड कार्ड से लैस हैं, जिसका अर्थ है ध्वनि तरंग के एक नमूने को एन्कोड करने के लिए 16 बाइनरी अंकों का उपयोग करना।
एक ऑडियो फ़ाइल चलाने के लिए, कंप्यूटर बाइनरी कोड के प्रोग्राम किए गए अनुक्रमों को संसाधित करता है और उन्हें एक निरंतर तरंग में जोड़ता है। 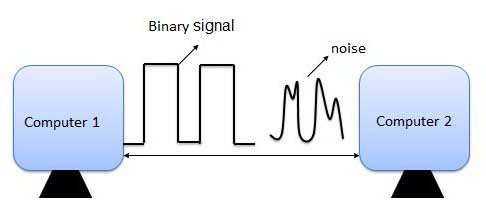
ग्राफिक्स एन्कोडिंग
PowerPoint में ग्राफिक जानकारी को चित्र, आरेख, चित्र या स्लाइड के रूप में प्रस्तुत किया जा सकता है। किसी भी चित्र में छोटे डॉट्स - पिक्सेल होते हैं, जिन्हें विभिन्न रंगों में चित्रित किया जा सकता है। प्रत्येक पिक्सेल का रंग एन्कोडेड और संग्रहीत होता है, और परिणामस्वरूप हमें एक पूर्ण छवि मिलती है।
यदि चित्र श्वेत और श्याम है, तो प्रत्येक पिक्सेल का कोड एक या शून्य हो सकता है। यदि 4 रंगों का उपयोग किया जाता है, तो उनमें से प्रत्येक के कोड में दो अंक होते हैं: 00, 01, 10 या 11. इस सिद्धांत से, किसी भी छवि के प्रसंस्करण की गुणवत्ता प्रतिष्ठित होती है। चमक बढ़ने या घटने से भी उपयोग किए जाने वाले रंगों की संख्या प्रभावित होती है। सबसे अच्छा, कंप्यूटर लगभग 16,777,216 रंगों को अलग करता है।

निष्कर्ष
प्रोग्रामिंग जानकारी के विभिन्न तरीके हैं, जिनमें बाइनरी कोडिंग सबसे प्रभावी है। केवल दो वर्णों - 1 और 0 - के साथ कंप्यूटर अधिकांश फ़ाइलों को आसानी से पढ़ सकता है। उसी समय, प्रसंस्करण की गति उपयोग की जाने वाली तुलना में बहुत अधिक है, उदाहरण के लिए, दशमलव प्रणालीप्रोग्रामिंग। इस पद्धति की सरलता इसे किसी भी तकनीक के लिए अपरिहार्य बनाती है। यही कारण है कि बाइनरी एन्कोडिंग अपने समकक्षों के बीच सार्वभौमिक है।