Как кодируются буквы в двоичной системе. Что такое двоичный код? Как текстовая информация может выглядеть в памяти компьютера
Двоичное кодирование текстовой информации
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, то есть I = 1 байт = 8 битов.
Эммануэль из Нигерии спрашивает: «Как преобразуются буквы в двоичные коды?». Если это так, вы зададите отличный вопрос, потому что вопрос о том, как мы конвертируем буквы, на самом деле не объясняется там. Большой вопрос: «Как вы конвертируете письмо в число?» Потому что, если вы можете конвертировать письмо в число, то вы можете использовать информацию на нашей базовой странице конверсии, чтобы преобразовать это число в двоичный. Итак, как компьютер выполняет преобразование из буквы в цифру?
Каждый символ должен иметь одинаковое количество двоичных битов - иначе никто не узнает, где заканчивается один символ, а следующий начинается. Мы помещаем пробел между каждыми четырьмя датами, по той же причине, что и мы, запятые в базе десять - это помогает нам легче читать длинные строки цифр.
Для кодирования одного символа требуется 1 байт информации.
Если рассматривать символы как возможные события, то по формуле (2.1) можно вычислить, какое количество различных символов можно закодировать:
N = 2 I = 2 8 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Хорошо, так что с этого момента, теперь нам просто нужно знать, какие буквы представлены каким числом. Вот вам краткая справка. Это означает, что строчные буквы имеют другой номер, назначенный, чем буквы верхнего регистра. Теперь есть пара вещей, о которых вы могли бы подумать, например: «Что происходит до 65 лет?» и «Почему существует разрыв между верхним и нижним регистром?».
Ответ на первый вопрос заключается в том, что в этих пробелах присутствуют другие символы - цифры, знаки препинания, специальные контрольные символы. Причина, по которой существует разрыв между верхним регистром и нижним регистром алфавитов, заключается в том, что он составляет «32» больше, чем «А.». Это очень удобно, потому что 32 - это сила 2, поэтому изменение между верхним и нижним регистром означает изменение просто один бит.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертаниям, а компьютер - по их кодам.
При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт.
Почему вы хотите это сделать? Ну, вы, вероятно, не сделали бы, если бы не хотели сохранить пространство, и вы не заботились ни о чем, кроме основного алфавита верхнего регистра. Понимаете, если все, о чем вы заботитесь, это письма в верхнем регистре, вы можете сделать такое преобразование следующим образом.
Двоичное кодирование звуков
Потому что теперь ваше самое большое число, которое вам нужно кодировать, составляет 26, что меньше 2 5. Это означает, что вам нужно всего пять цифр, чтобы писать каждый номер вместо восьми! Вы сэкономите около 38% места на странице. Поскольку у вас должно быть место в таблице на 32 символа, и вы использовали только до 26, вы могли бы также использовать другие. Может быть, есть некоторые знаки препинания?
В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее).
Почему в компьютере используется двоичный код
Или вы можете создать таблицу с 64 символами, которая либо позволит вам добавить намного больше знаков препинания, или цифр, или алфавита в нижнем регистре. Но теперь вы используете шесть двоичных цифр на символ, поэтому вы не сохраняете столько места.
Или вы можете полностью перепутать свою диаграмму персонажа, что затрудняет для других людей декодирование. Это похоже на компьютер, состоящий из нескольких световых переключателей, и каждый световой переключатель управляет только одной лампочкой. Скажем, у вас было два световых переключателя. Есть четыре разных способа, которыми мы могли бы перевернуть эти переключатели.
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы. К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO - табл. 1.3), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
Двоичный код принимает каждую из этих комбинаций и присваивает ему номер, например. Если бы мы добавили в другую лампочку, мы бы поставили ее в два раза больше, чем указатель 2. Затем, если бы все луковицы были включены, значение точки было бы равно 4 2 1 = И если бы мы добавили в другую лампу, мы бы поставили ее на 8 пунктов. Как вы можете видеть, это займет много лампочек, чтобы сделать действительно большой номер!
Наконец, хотя мы даем точечные значения каждой из этих лампочек, когда мы записываем их, мы все же записываем их только как единицы и нули. Один означает «Вкл.», А «Нуль» означает «Выкл.». Так что, допустим, у нас было 8 лампочек, и они были настроены так.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = = 65536 различных символов. Эту кодировку поддерживают последние версии платформы Microsoft Windows&Office (начиная с 1997 года).
Каждая кодировка задается своей собственной кодовой таблицей. Как видно из табл. 1.3, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Точечные значения этих восьми ламп. Поэтому мы бы сказали, что последовательность луковиц стоит. Перейдите и введите текст в кодировщик. Компьютер преобразует эти буквы в числа, а затем преобразует эти числа в двоичные! Знаете ли вы, что для написания любой буквы на компьютере требуется 8 лампочек? Таким образом, слово с 5 буквами займет 40 лампочек! Сколько лампочек вы думаете, чтобы сделать эту страницу?
Как текстовая информация может выглядеть в памяти компьютера?
Все данные внутри компьютера передаются как серия электрических сигналов, которые либо включены, либо выключены. Поэтому для того, чтобы компьютер мог обрабатывать любые данные, включая текст, изображения и звук, они должны быть преобразованы в форму. Если данные не преобразуются в двоичные - серия из 1 и 0, компьютер просто не поймет это или не сможет обработать его.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово "ЭВМ", тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Когда нажата любая клавиша на клавиатуре, ее необходимо преобразовать в двоичное число, чтобы ее можно было обработать с помощью компьютера, и типичный символ может появиться на экране. Код, в котором каждое число представляет символ, может использоваться для преобразования текста в двоичный. Вызывается один код, который мы можем использовать для этого.
Если вы хотите использовать акценты на европейских языках или более крупные алфавиты, такие как кириллица и китайский мандарин, вам нужно больше символов. Поэтому был создан другой код, называемый. Это означало, что компьютеры могут использоваться людьми, использующими разные языки.
Определение числового кода символа
1. Запустить текстовый редактор MS Word 2002. Ввести команду [Вставка-Символ...]. На экране появится диалоговая панель Символ . Центральную часть диалогового окна занимает таблица символов для определенного шрифта (например, Times New Roman).
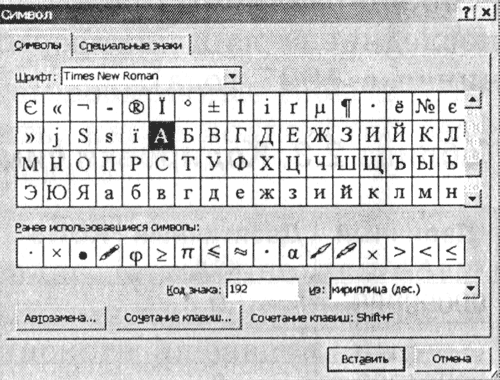 |
Символы располагаются последовательно слева направо и построчно, начиная с символа Пробел в левом верхнем углу и кончая буквой "я" в правом нижнем углу таблицы.
Двоичное кодирование текстовой информации
7-битный набор символов, используемый для представления символов английской клавиатуры. двоичная система чисел, которая содержит две цифры, 0 и также известна как базовый бит. Способ уменьшения размеров файлов, особенно на цифровых носителях, таких как фотографии, аудио и видео. данные Единицы информации. При вычислении могут быть разные типы данных, включая целые числа, символы и логические. Система номеров, наиболее часто используемая людьми. Он содержит 10 уникальных цифр 0 до также известен как десятичная или базовая цифровая информация, хранящаяся как дискретные значения, обычно представляемые в виде чисел. Это набор данных, который описывает и дает информацию о других данных. Совместимость с большинством медиаплееров. Разработано группой экспертов по движущимся изображениям - пиксель слоя. Элемент изображения - одна точка цвета в цифровом растровом изображении или на экране компьютера. разрешение. Точность детализации, которая может быть видна на изображении, - чем выше разрешение изображения, тем больше деталей оно выполняется. Он измеряется в точках на дюйм. частота выборки. Сколько выборок данных принимается в секунду. Обычно это измеряется в герцах, например, аудиофайл обычно использует образцы 1 кГц. При кодировании, когда числа, буквы или слова представлены определенной группой символов, говорят, что число, буква или слово кодируются.
Выбрать символ и в раскрывающемся списке из: тип кодировки. В текстовом поле Код знака: появится его числовой код.
Ввод символов по числовому коду
1. Запустить стандартную программу Блокнот . С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 0224, отпустить клавишу {Alt}. В документе появится символ "а". Повторить процедуру для числовых кодов от 0225 до 0233. В документе появится последовательность из 12 символов "абвгдежзий" в кодировке Windows (CP1251).
Группа символов называется кодом. Цифровые данные представляются, сохраняются и передаются как группа двоичных битов. Эта группа также называется двоичным кодом. Двоичный код представлен числом, а также буквенно-цифровой буквой. Ниже приведен список преимуществ, которые предлагает двоичный код.
Классификация двоичных кодов
Двоичные коды делают анализ и проектирование цифровых схем, если мы используем двоичные коды.
- Двоичные коды подходят для компьютерных приложений.
- Двоичные коды подходят для цифровой связи.
2. С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 224, в документе появится символ "р". Повторить процедуру для числовых кодов от 225 до 233, в документе появится последовательность из 12 символов "рстуфхцчшщ" в кодировке MS-DOS (CP866).
 |
Практические задания
Дробные числа со знаком
Несколько систем кодов используются для выражения десятичных цифр 0 через. В этих кодах каждая десятичная цифра представлена группой из четырех бит. В этом типе двоичных кодов позиционные веса не назначаются. Это невзвешенный код, используемый для выражения десятичных чисел. Коды избытка-3 получают следующим образом.

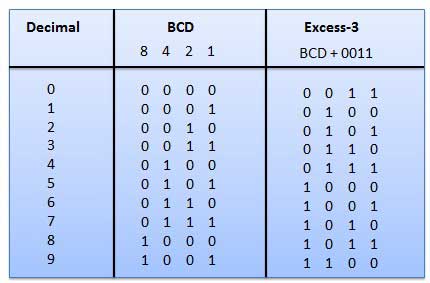
Это невзвешенный код, и это не арифметические коды. Это означает, что нет конкретных весов, назначенных для позиции бит. Он имеет очень особенную особенность: только один бит будет меняться каждый раз, когда десятичное число будет увеличено, как показано на рис. Поскольку изменяется только один бит за раз, серый код вызывается как единичный код расстояния. Серый код - это циклический код. Серийный код не может использоваться для арифметической операции.
1.29. Используя таблицу символов (MS Word), записать последовательность десятичных числовых кодов в кодировке Windows (СР1251) для слова "компьютер".
1.30. Используя Блокнот, определить, какое слово в кодировке Windows (СР1251) задано последовательностью числовых кодов: 225, 224, 233,242.
1.31. Какие последовательности букв будут в кодировках КОИ8 и ISO соответствовать слову "ЭВМ", записанному в кодировке СР1251?
Двоичный кодированный десятичный код
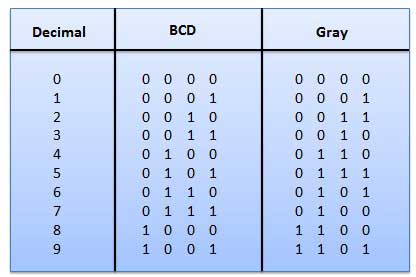
Датчик положения вала создает кодовое слово, которое представляет собой угловое положение вала. Серый код широко используется в кодовых датчиках положения вала.
. В этом коде каждая десятичная цифра представлена 4-битным двоичным числом. 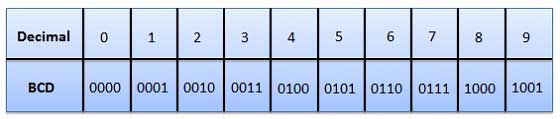
- Он очень похож на десятичную систему.
- Нам нужно помнить только двоичный эквивалент десятичных чисел от 0 до 9.
Компьютер обрабатывает большое количество информации. Аудиофайлы, картинки, тексты - все это необходимо воспроизвести или вывести на экран. Почему двоичное кодирование является универсальным методом программирования информации любого технического оборудования?
Чем отличается кодирование от шифрования?
Зачастую люди отождествляют понятия "кодирование" и "шифрование", когда на самом деле они имеют разный смысл. Так, шифрованием называют процесс преобразования информации с целью ее сокрытия. Расшифровать зачастую может сам человек, который изменил текст, или специально обученные люди. Кодирование же применяется для обработки информации и упрощения работы с ней. Обычно используется общая таблица кодировки, знакомая всем. Она же встроена в компьютер.
Эти символы должны представлять 26 алфавитов с большими и малыми буквами, цифры от 0 до 9, знаки препинания и другие символы. Буквенно-цифровые коды - это коды, которые представляют числа и буквенные символы. В большинстве случаев такие коды также представляют другие символы, такие как символ и различные инструкции, необходимые для передачи информации. Алфавитно-цифровой код должен содержать не менее 10 цифр и 26 букв алфавита, т.е. всего 36 элементов. Следующие три буквенно-цифровых кода очень часто используются для представления данных.
Кодирование изображений в двоичный код
Эта система кодирования информации называется двоичной. Это форма кодирования, которая позволяет компьютерам работать. В двоичном коде используются два состояния для кодирования информации. Это называется «десятичной базой». Однако более старые цивилизации и даже некоторые современные приложения используют и используют другие базы чисел.
Принцип двоичного кодирования
Двоичное кодирование основывается на использовании всего лишь двух символов - 0 и 1 - для обработки информации, используемой различными устройствами. Эти знаки назвали двоичными цифрами, на английском - binary digit, или bit. Каждый из символов занимает память компьютера в 1 бит. Почему двоичное кодирование является универсальным методом обработки информации? Дело в том, что компьютеру легче обрабатывать меньшее количество символов. От этого напрямую зависит и продуктивность работы ПК: чем меньше функциональных задач нужно выполнить устройству, тем выше скорость и качество работы.
Принцип двоичного кодирования встречается не только в программировании. С помощью чередования глухих и звонких ударов барабана жители Полинезии передавали информацию друг другу. Сходный принцип применяется и в где для передачи сообщения используются длинные и короткие звуки. «Телеграфная азбука» используется и сегодня.
Где используется двоичное кодирование?
Двоичное в компьютере используется повсеместно. Каждый файл, будь то музыка или текст, должен быть запрограммирован, чтобы в последующем он мог быть легко обработан и прочитан. Система двоичного кодирования полезна для работы с символами и числами, аудиофайлами, графикой.
Двоичное кодирование чисел
Сейчас в компьютерах числа представлены в закодированном виде, непонятном для обычного человека. Использование арабских цифр так, как мы себе представляем, для техники нерационально. Причиной тому является необходимость присваивать каждому числу свою неповторимый символ, что сделать порой невозможно.

Существуют две системы счисления: позиционная и непозиционная. Непозиционная система основана на использовании латинских букв и знакома нам в виде Такой способ записи достаточно сложен для понимания, поэтому от него отказались.
Позиционная система счисления используется и сегодня. Сюда входит двоичное, десятичное, восьмеричное и даже шестнадцатеричное кодирование информации.
Десятичной системой кодирования мы пользуемся в быту. Это привычные для нас которые понятны каждому человеку. Двоичное кодирование чисел отличается использованием только нуля и единицы.
Целые числа переводятся в двоичную систему кодирования путем деления их на 2. Полученные частные также поэтапно делятся на 2, пока не получится в итоге 0 или 1. Например, число 123 10 в двоичной системе может быть представлено в виде 1111011 2 . А число 20 10 будет выглядеть как 10100 2 .
Индексы 10 и 2 обозначаются, соответственно, десятичную и двоичную систему кодирования чисел. Символ двоичного кодирования используется для упрощения работы со значениями, представленными в разных системах счисления.
Методы программирования десятичных чисел основаны на “плавающей запятой”. Для того чтобы правильно перевести значение из десятичной в двоичную систему кодирования, используют формулу N = M х qp. М - это мантисса (выражение числа без какого-либо порядка), p - это порядок значения N, а q - основание системы кодирование (в нашем случае 2).
Не все числа являются положительными. Для того чтобы различить положительные и отрицательные числа, компьютер оставляет место в 1 бит для кодирования знака. Здесь ноль представляет знак плюс, а единица - минус.
Использование такой системы счисления упрощает для компьютера работу с числами. Вот почему двоичное кодирование является универсальным при вычислительных процессах.

Двоичное кодирование текстовой информации
Каждый символ алфавита кодируется своим набором нулей и единиц. Текст состоит из разных символов: букв (прописных и строчных), арифметических знаков и других различных значений. Кодирование текстовой информации требует использования 8 последовательных двоичных значений от 00000000 до 11111111. Таким образом можно преобразовать 256 различных символов.
Чтобы не было путаницы в кодировании текста, используются специальных таблицы значений для каждого символа. В них присутствует латинский алфавит, арифметические знаки и знаки особого назначения (например, €, ¥, и другие). Символы промежутка 128-255 кодируют национальный алфавит страны.
Для кодирования 1 символа требуется 8 бит памяти. Для упрощения подстчетов 8 бит приравниваются к 1 байту, поэтому общее место на диске для текстовой информации измеряется в байтах.

Большинство персональных компьютеров оснащены стандартной таблицей кодировки ASCII (American Standard Code for Information Interchange). Также используются другие таблицы, в которых система кодирования текстовой информации отличается. К примеру, первая известная кодировка символов называется КОИ-8 (код обмена информацией 8-битный), и работает она на компьютерах с ОС UNIX. Также широко встречается таблица кодов СР1251, которая была создана для операционной системы Windows.
Двоичное кодирование звуков
Еще одна причина, почему двоичное кодирование является универсальным методом программирования информации, - это его простота при работе с аудиофайлами. Любая музыка представляет собой звуковые волны разной амплитуды и частоты колебания. От этих параметров зависит громкость звука и его высота тона.
Чтобы запрограммировать звуковую волну, компьютер делит ее условно на несколько частей, или «выборок». Число таких выборок может быть большим, поэтому существует 65536 различных комбинаций нулей и единиц. Соответственно, современные компьютеры оснащены 16-битными звуковыми картами, что означает использование 16 двоичных цифр для кодирования одной выборки звуковой волны.
Чтобы воспроизвести аудиофайл, компьютер обрабатывает запрограммированные последовательности двоичного кода и соединяет их в одну непрерывную волну.
Кодирование графики
Графическая информация может быть представлена в виде рисунков, схем, картинок или слайдов в PowerPoint. Любая картинка состоит из мелких точек - пикселей, которые могут быть окрашены в разный цвет. Цвет каждого пикселя кодируется и сохраняется, и в итоге мы получаем полноценное изображение.
Если картинка черно-белая, код каждого пикселя может быть либо единицей, либо нулем. Если используется 4 цвета, то код каждого из них состоит из двух цифр: 00, 01, 10 или 11. По этому принципу различают качество обработки любого изображения. Увеличение или уменьшение яркости также влияет на количество используемых цветов. В лучшем случае компьютер различает около 16 777 216 оттенков.

Заключение
Существуют разные методы программирования информации, среди которых двоичное кодирование является наиболее эффективным. Всего лишь с помощью двух символов - 1 и 0 - компьютер легко прочитывает большинство файлов. При этом скорость обработки намного выше, нежели использовалась бы, например, десятичная система программирования. Простота этого метода делает его незаменимым для любой техники. Вот почему двоичное кодирование является универсальным среди своих аналогов.



